Welcome to the homepage of the
Mathematical Optimization for Data Science Group
Department of Mathematics and Computer Science, Saarland University, Germany
|
Seminar on Machine Learning for Optimization |
|
Lecturer: Peter Ochs Summer Term 2024 Seminar for Mathematics and Computer Science 7 ECTS Time: Tuesday 2 - 4 pm. First meeting: 23.04.2023 Teaching Assistants: Camille Castera and Sheheryar Mehmood Language: English Prerequisites: Basics of Mathematics (e.g. Linear Algebra 1-2, Analysis 1-3, Mathematics 1-3 for Computer Science) Basic understanding of Optimization Basics of Machine Learning are recommended but not required. |
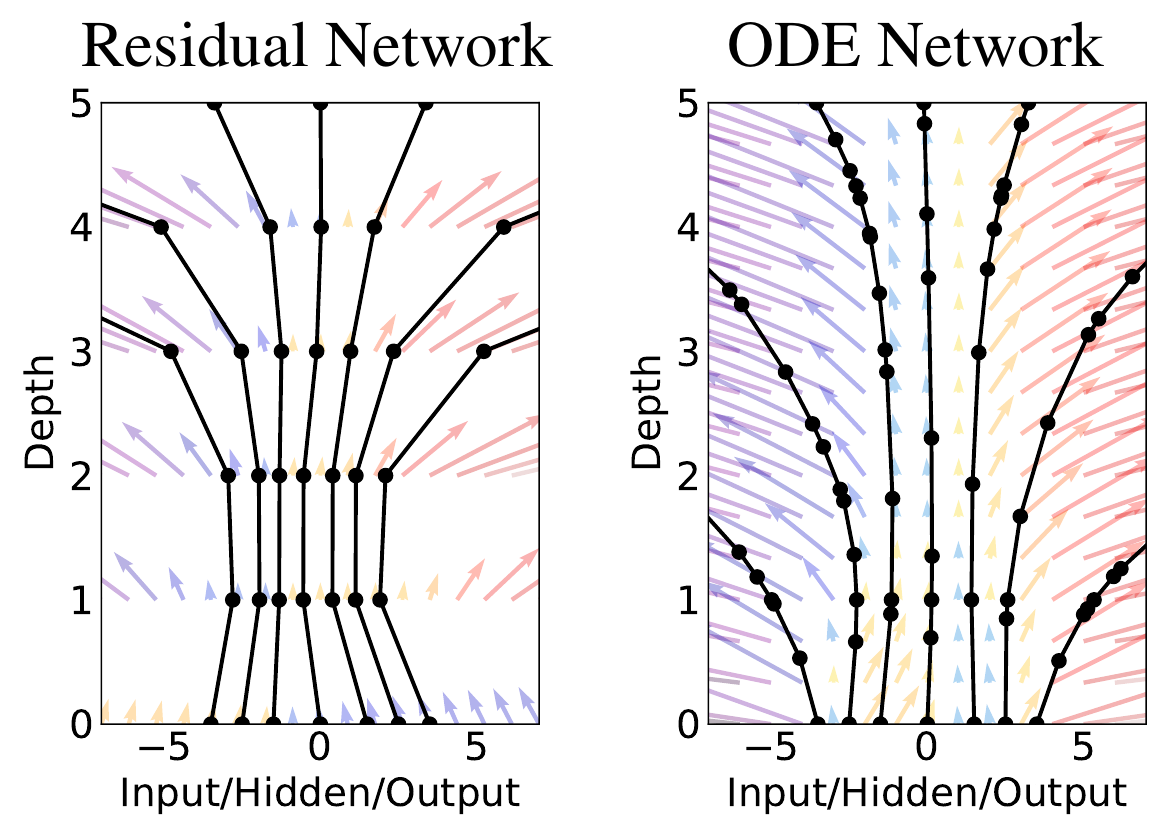 [Chen et al. 2018] |
| |||||
| News | |||||
|
08.04.2024: Table of references uploaded. 11.03.2024: Webpage is online. | |||||
| Description | |||||
| The recently growing field of Learning to optimize (L2O) leverages machine learning techniques to develop optimization methods and shares close relations to Meta-Learning. While classic optimization algorithms are hand crafted and proved to work for certain classes of problems, L2O automates the design based on a (training) data set of typical problems. L2O approaches are data-driven and are therefore tailored to a specific distribution of problems. On one hand, this is achieved by exploiting statistical features and unlocks solution strategies that outperform classical optimization algorithms by several orders of magnitude, however, on the other hand, usually there is no or little theoretical guarantees on the actual performance for a new problem. Generalization bounds like in Empirical Risk Minimization of Statistical Learning in general can be employed to provide some evidenve for in-distribution problems. However, typically such an approach is prone to fail for out-of-distribution problems. Therefore, the worlds of L2O and classical optimization must be brought closer together to achieve reliability and speed at the same time. In this seminar, we explore some important research attempts in the world of L2O. | |||||
| Registration: | |||||
|
Register via the Seminar Assignment System at SIC Seminars. For students from mathematics who cannnot register via this system, please write an eMail to Peter Ochs. | |||||
| Requirements for Successful Participation: | |||||
|
Format: (in-person participation only) Each student is assigned to three papers (assigned by us): one student gives the presentation on the paper, and the two other students take the role of moderators, i.e., they lead the discussion after the presentation. Rules:
| |||||
| Documentation and Schedule: | |||||
MOP Group
©2017-2026
The author is not
responsible for
the content of
external pages.